Components of the Lemur Toolkit
Contents
1. Basic Components
The following table summarizes some of the key components of the toolkit.
| Name | Description |
|---|---|
| Document DocumentStream |
A Document is an abstract representation of raw text. A DocumentStream is the input stream that is fed into the indexer. Transforming raw text into a Document representation will perform any required tokenization, stemming, or morphological processing that will be used by the resulting language models and retrieval methods. |
| Query | A Query represents an abstract query which can be a piece of text or structured query, such as a boolean query. |
| PushIndex | This is an abstract API for building indices by pushing documents and terms into an indexer, instead of pulling documents from a DocumentStream. |
| Index | This is the abstract class representing an index. In a basic index for language models this will contain a word-to-document list as well as a document-to-word list. More detailed indices may include word position information. |
| Counter | This is the basic class used to construct language models, and other document representations in a retrieval model. For example, an instance of Counter may hold the word counts (term frequencies) for all of the words in a document. |
| UnigramLM | UnigramLM is a language model, assigning a probability to each word in a lexicon. A UnigramLM may be constructed from a Counter, or another UnigramLM together with a Counter using some smoothing scheme. |
| DocumentRep | This class is used to encode the particular way a document is represented in a given retrieval method. Conceptually, a vector space model may use one document representation, a basic LM retrieval method may use another, although each may be built upon the same index. |
| QueryRep | Analogous to a DocumentRep, this is how a query is represented in a particular method. For a standard vector space model or language model retrieval method, this would be very similar to the partner document representation, however for structured queries it would be quite different. A QueryRep is generated typically from a Query. |
| TextQueryRep | TextQueryRep inherits from QueryRep and represents a query by a set of weighted terms, which is usually appropriate for a text query. TextQueryRep is usually constructed based on a text query. |
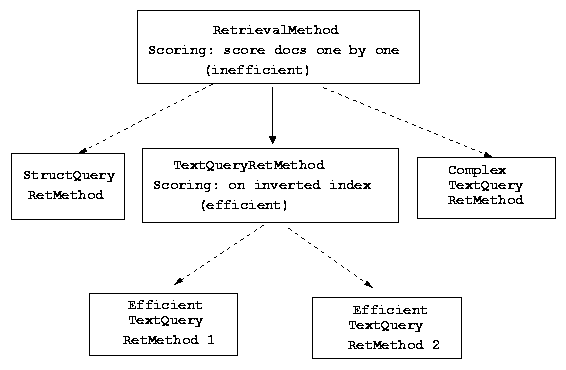
| RetrievalMethod | There are four essential member functions required by a RetrievalMethod, which is constructed on top of an Index: (1) generate a QueryRep based on a given Query. (2) compute a score based on a given QueryRep and a document ID. (This makes it possible to score any subset of documents one-by-one, useful when re-ranking documents with a complex retrieval method.) (3) compute the scores of all documents in the collection for a given QueryRep. (This makes it possible for a subclass to implement a scoring strategy more efficiently, e.g., based on an inverted index.) (4) update a given QueryRep based on a set of (presumably relevant) documents. |
| TextQueryRetMethod | TextQueryRetMethod inherits from RetrievalMethod and provides a generic implementation of efficient scoring based on an inverted index. There are four essential member functions required by a TextQueryRetMethod: (1) For a given document id, the TextQueryRetMethod should be able to return an appropriate DocumentRep. (2) (Similarly) for a given piece of query text it should be able to return a TextQueryRep. (3) It must provide a ScoreFunction that will evaluate the "similarity" between a given DocumentRep and TextQueryRep. (4) It must also implement a query updating method appropriate for the particular TextQueryRep used in the TextQueryRetMethod. |
The following section describes in more detail how these components interact with each other.
2. Interactions Between Components
Indexing and Building Language Models. The figure below is a sketch of the dependencies between the various components. In this figure, the arrows are not meant to be precise in the sense of input/output relations in the code, but are rather intended to suggest how objects are typically built, as explained below.
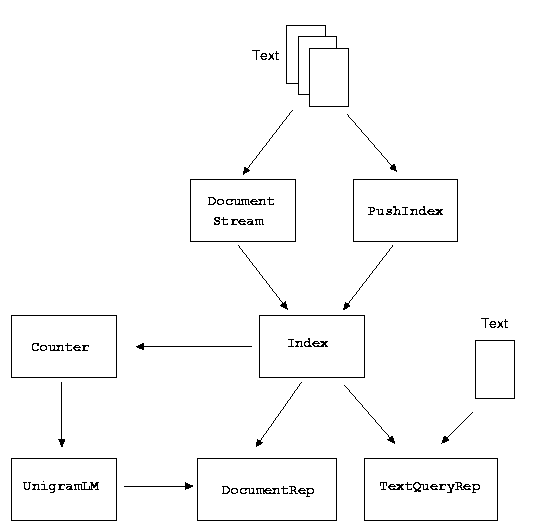
A DocumentStream is built from raw text. Each text document, as defined by the user, is mapped to a Document object, and this mapping is responsible for all tokenization, stemming, etc. From a stream of documents, vocabularies of terms and document ids are constructed, and an inverted index is created.
Alternatively, an index can be created using a "push" mode. An indexer, in this case, does not handle the text directly; rather the application tells the indexer when to begin a doc and to add terms. The class PushIndex defines the general abstract interface for such capabilities. The application is responsible for all tokenization and stemming of the tokens before sending them to a PushIndex. Multiple indexes can be created simultaneously from the same text handling process by "pushing" the (same or different) tokens to different instances of a PushIndex.
Once an index is created, language models can be built from individual documents or sets of documents in the collection. One way for a language model to be constructed is to first create a Counter instance for a document, representing the empirical counts of words in the document. From the counts, an actual model (UnigramLM) is then formed by applying an appropriate smoothing algorithm. Language models can also be built by smoothing together other language models, without going directly through a Counter object.
In order to implement a particular retrieval framework, a document representation and a query representation must be designed. One of the roles of the DocumentRep and TextQueryRep classes is to ensure that a retrieval method is applied to the appropriate types of objects; that is, that a language model engine is not evaluated on documents represented in according to a TFIDF model. (The lack of typing support in C++ makes this difficult to implement in an elegant way.) The document and query representation may precompute collection statistics, such as inverse document frequency or backoff weights for smoothing. In the figure above, there are arrows into DocumentRep from both the Index and UnigramLM, since the representation of a document is built in terms of a particular collection index, but the representation may also depend on a background language model for smoothing. There are arrows into TextQueryRep from both raw text and Index since the query is typically formed from raw text, but the Index is used to ensure consistency of the lexicon, tokenization, etc., and in order to have access to smoothing methods or inverse document frequency statistics.
Making a Retrieval Method for Text Queries.
The class TextQueryRetMethod implements a generic efficient scoring procedure (with inverted index), based on a TextQueryRep, a DocumentRep and a ScoreFunction. The following diagram sketches the design:
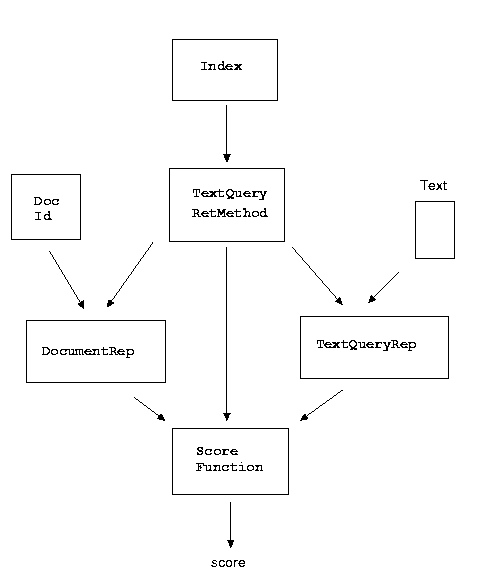
A particular TextQueryRetMethod must provide three basic functions. First, the class must provide a function that, given a document identifier, returns a DocumentRep instance to represent the corresponding document. Similarly, it must provide a function that, given the query text, returns a TextQueryRep instance to represent the query. In addition, it must provide a function that returns a ScoreFunction instance. The ScoreFunction is used in TextQueryRetMethod to compute a numeric score based on a DocumentRep and a TextQueryRep. The class must also implement a query updating method appropriate for the particular TextQueryRep used in the retrieval method.
Most of the practical/efficient retrieval methods can be added to the toolkit by subclassing TextQueryRetMethod. Specifically, one generally needs to create the following classes:
- A method-specific query representation by subclassing the abstract TextQueryRep
- A method-specific document representation by subclassing the abstract DocumentRep
- A method-specific score function by subclassing the abstract ScoreFunction
- A subclass of the abstract TextQueryRetMethod to coordinate the interactions of the document representation, query representation, and scoring function, as well as to implement feedback methods.
The toolkit comes equipped with TextQueryRetMethods that implement a basic TFIDF vector space model, Okapi, and a language modeling method using the Kullback-Leibler similarity measure between document and query language models.
Adding an Arbitrary Retrieval Method.
When a retrieval method can not be implemented efficiently by scoring on the inverted index, there would be little benefit to subclass TextQueryRetMethod. In this case, it is better to subclass the most general abstract class RetrievalMethod. Similarly, when the query can not be represented by a set of weighted terms, e.g., in the case of structured queries, it is also more natural to subclass RetrievalMethod. In any case, as long as the new retrieval method is added as a subclass of RetrievalMethod, it will be accessible to all retrieval applications that work on the general interface provided by RetrievalMethod.
The following diagram illustrates different possibilities for adding a new retrieval method (linked with broken lines).